Efficient Trie Searches
Summary
It's my understanding Bagwell's work was important in the development of the so called persistent data structures popularized by the Clojure programming language. I hope to learn a bit more about this history by reading the paper Fast and Space Efficient Trie Searches.
Notes
Interesting quote in the intro:
These algorithms were originally conceived as the basis for fast scanners in language parsers where the essence of lexicon recognition is to associate a sequence of symbols with a desired semantic.
Points out the space inefficiencies of a naive / directly indexed m-way trie, where you take the ordinal value of each letter in the key. Space is proportial to \(s^p\) where \(s\) is alphabet cardinality, and \(p\) is length of the keys.
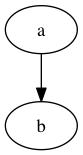
Bagwell describes a simple search function which starts at the root node and proceeds through each sub-trie until it fails or reaches the value.
// Generic Key Search in a trie based Dictionary int Find(char *Key) { TNode *P,*C; P=Root; while (C=Next(P,*Key)) { Key++; P=C; } if (*Key==0) return P->Value; return 0; }
This isolates the area which we want to make more efficient to the
Next(node, key) function which is responsible for finding the next
sub-trie.
Quick Graph
Let's show off!